-
×
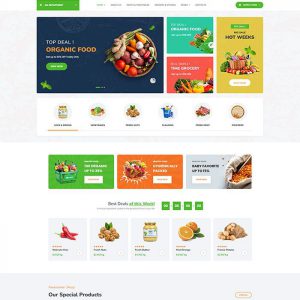 Website template for Fd1991 Food
10 × $29.00
Website template for Fd1991 Food
10 × $29.00 -
×
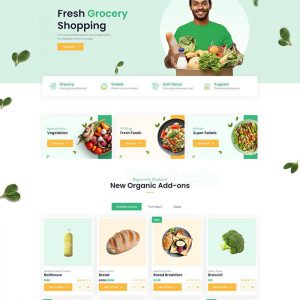 Website template for Fd1924 Food
6 × $29.99
Website template for Fd1924 Food
6 × $29.99 -
×
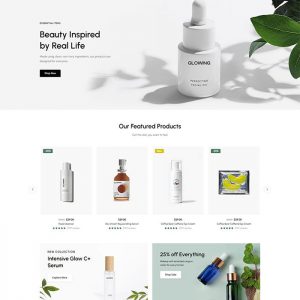 Website template for TXR2945 spa and beauty institute.
5 × $26.50
Website template for TXR2945 spa and beauty institute.
5 × $26.50 -
×
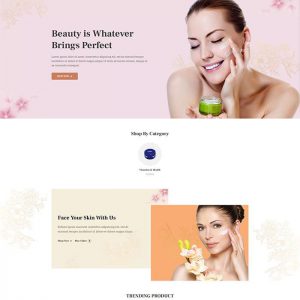 Website template for SPX1304 spa and beauty institute.
7 × $30.00
Website template for SPX1304 spa and beauty institute.
7 × $30.00 -
×
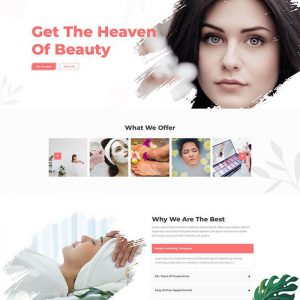 Website template for DNSK138 spa and beauty institute.
6 × $26.50
Website template for DNSK138 spa and beauty institute.
6 × $26.50 -
×
 Set up a website for selling pet supplies.
7 × $35.00
Set up a website for selling pet supplies.
7 × $35.00 -
×
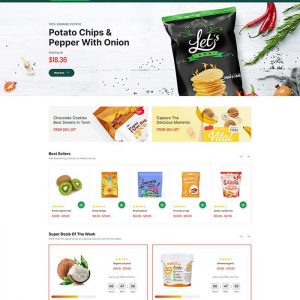 Food supermarket website template FD251
2 × $25.00
Food supermarket website template FD251
2 × $25.00 -
×
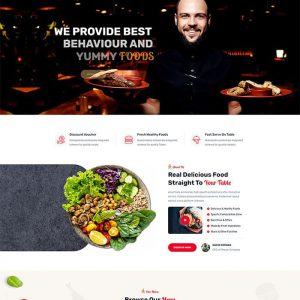 Restaurant website template BHTP242
4 × $26.50
Restaurant website template BHTP242
4 × $26.50 -
×
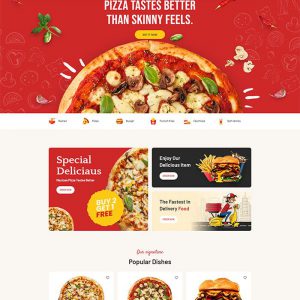 Install the pizza restaurant website template BHTP251
4 × $24.99
Install the pizza restaurant website template BHTP251
4 × $24.99 -
×
 Auto Crawler Product from Amazon Windows Only
3 × $26.99
Auto Crawler Product from Amazon Windows Only
3 × $26.99 -
×
 Build website marketing style 2
1 × $35.00
Build website marketing style 2
1 × $35.00 -
×
 Buid website Marketing Style 1
1 × $26.00
Buid website Marketing Style 1
1 × $26.00 -
×
 Auto generate Design for Redbubble Teepublic Speardshirt
2 × $26.50
Auto generate Design for Redbubble Teepublic Speardshirt
2 × $26.50 -
×
 Amazon Bulk Custom Tools
1 × $29.99
Amazon Bulk Custom Tools
1 × $29.99 -
×
 Etsy Clone and Upload Tools
1 × $26.90
Etsy Clone and Upload Tools
1 × $26.90
Subtotal: $1.724.26